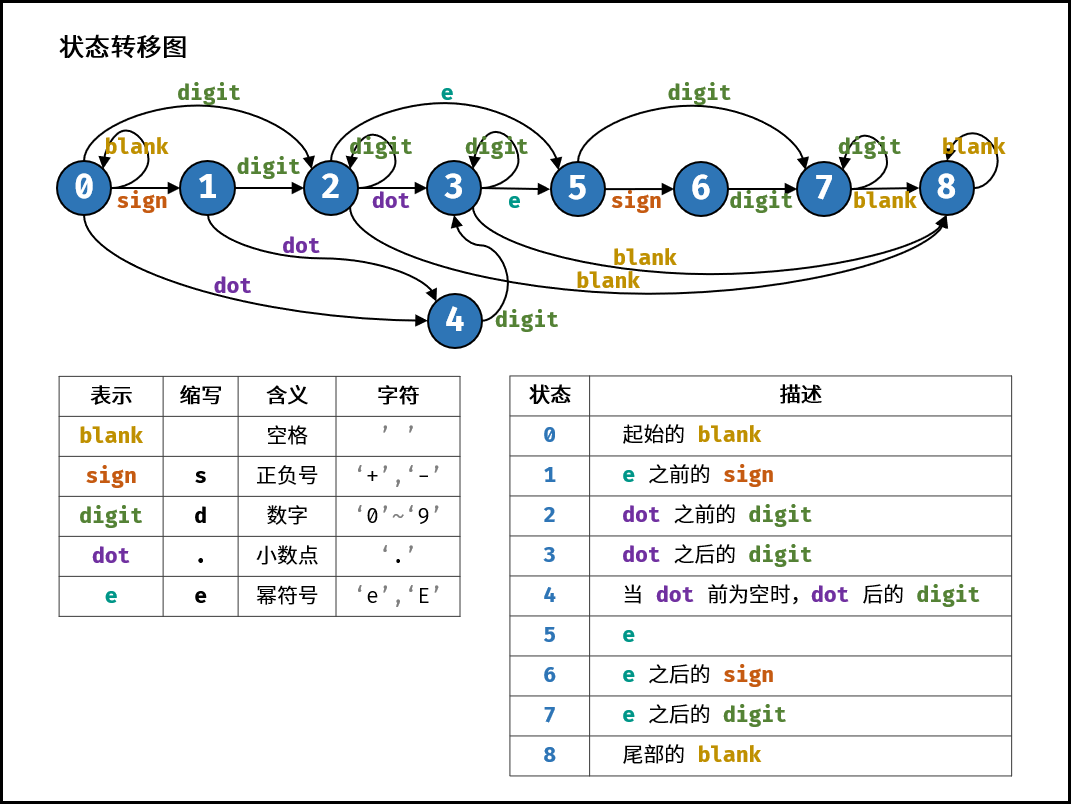
概述
哈希化是一种常见的数据存储方式,可以把一堆数据存到一起,并在O(1)复杂度下检索其中的任意一项。而对于字符串来说,普通的unordered_set<string>在哈希的时候会对整个字符串进行遍历,今天做到的这道题会因此TLE。
在需要对某个字符串的子字符串进行哈希时,可以对整个字符串进行一个预处理,使后续的哈希从伪O(1)实O(n)降低为真正的O(1)。
原理
字符串哈希将整个字符串看作一个base进制的数,这个base一般会取一个足够大的质数,例如1331、13331等。为方便理解,我们先取base为10,并取字符串s = "123456"。
如果我想得到s[1:2]的哈希值(即23),我们可以先取得s[0:2]的哈希值(记为h[2]),即123,再减去多余的100即可。那这个100怎么来的呢?只需要将s[0]的值乘以若干次方(此处为2次)的base就可以了。根据这个原理,我们就可以得到一个通用的公式:h[l:r] = h[r] - h[l-1] * p[r - l + 1],其中h[l:r]表示字符串s下标从1开始数第l为和第r位之间的子串的哈希值,h[idx]表示字符串s前idx位的哈希值,p数组是次方数组,其内容为{1,base,base²,base³,...}。
由此,我们可以做到一次预处理,无数次O(1)哈希其子字符串,节省大量时间。
例题
LeetCode 1044. 最长重复子串
给你一个字符串 s ,考虑其所有 重复子串 :即 s 的(连续)子串,在 s 中出现 2 次或更多次。这些出现之间可能存在重叠。
返回 任意一个 可能具有最长长度的重复子串。如果 s 不含重复子串,那么答案为 "" 。
示例 1:
1 | 输入:s = "banana" |
示例 2:
1 | 输入:s = "abcd" |
题解
刚看到这道题的时候就傻眼了,除了暴力想不到什么可行的办法。一看评论区,"温馨提示, 今天这个打卡题出自136场周赛第四题, 当时国服只有6个人做出来,所以不会做很正常哦",原来大家都不会做,那我就放心了呀!
不过其实知道怎么做之后,这题还是没那么难的。虽然本题暴力验证每一个长度的子字符串存不存在重复非常的蠢,但是有了字符串哈希的技巧,验证其中某一个长度的子字符串存不存在重复却可以在O(n)的时间复杂度下完成。而且出现重复的可能性是单调递减的, 即待验证的子字符串长度越长,子字符串出现重复的可能性越小。所以我们可以对答案空间进行二分搜索,免去了大量的无用功。虽然不是第一次见这种技巧了,但有时就差这么tingle一下,想不到可以这么解。
还有一个技巧就是使用unsigned long long来储存哈希值,这样超过了2^64的时候就会自动取模,省的再做大数处理。(回忆起了周赛做了一个小时大数处理没做出来的恐惧[ac01])
代码:
1 | class Solution { |