1. 聊一聊智能指针
智能指针的作用是管理一个指针,避免申请的空间忘记释放导致内存泄漏。智能指针本质上是一个类模板,当超出了类的作用域时,类就会自动调用析构函数回收资源。C++里有四种智能指针:auto_ptr, unique_ptr, shared_ptr,和weak_ptr,其中auto_ptr 在C++11版本已经被废弃。
auto_ptr(已废弃)
auto_ptr 采用了所有权模式,后创建的指针会剥夺前面的指针的所有权。例如:
1 | auto_ptr<int> p1(new int(1)); |
p2会剥夺p1对指针的所有权,此时再访问p1就会出错。所以auto_ptr存在潜在的内存崩溃问题。
unique_ptr(代替auto_ptr)
unique_ptr采用独占式拥有概念,保证同一时间内之有一个智能指针可以指向该对象。例如:
1 | unique_ptr<int> p1(new int(1)); |
上面的代码无法通过编译,保证在编译期就将问题排查出来。此外,unique_ptr允许被一个临时的右值赋值,例如将上述第二行代码改为p2 = unique_ptr<int>(new int(1)),则可以通过编译,因为这样不会造成悬挂指针的情况。
shared_ptr
shared_ptr采用共享式拥有概念,多个shared_ptr可以指向相同的对象,并且只有最后一个指向它的shared_ptr被销毁时才会释放它占有的资源。
weak_ptr
weak_ptr是为了避免两个shared_ptr互相引用,导致其计数永远不会归零、资源永远不会被释放的死锁现象而引入的。它不控制对象的生命周期,不会改变计数器。weak_ptr没有重载*和->运算符,所以不能直接访问和修改引用的对象(可以通过lock()函数将其转化为shared_ptr然后再访问),但可以访问对象的引用数量等信息,它更像是一个shared_ptr的监控者。
2. 能不能自己实现一个shared_ptr?
自己封装一个类模板就行。需要实现构造函数和析构函数、拷贝构造函数和拷贝赋值函数,还有重载一些指针的操作符。
1 | class shared_cnt { |
3. 虚函数是什么原理?
每个包含虚函数的类(或者继承了包含虚函数的基类)都有一个自己的虚函数表,这个表是一个编译时就确定的静态数组。虚函数表包含了指向每个虚函数的函数指针。而编译器会在基类中定义一个隐藏的指针vptr,这是一个指向虚函数表的指针,在类对象创建的时候vptr 会设置成指向类的虚函数表。所以含有虚函数的类会多分配一个指针的大小。如果子类重写了基类的虚函数,就会将虚函数表中的函数指针覆盖为自己重写的函数以供调用。
如以下例子所示,基类Base有function1和function2两个函数,子类D1和D2分别重写了这两个函数。所以在D1的对象的虚函数表中,function1会指向自己重写的新函数,而function2会指向基类的function2,D2同理。
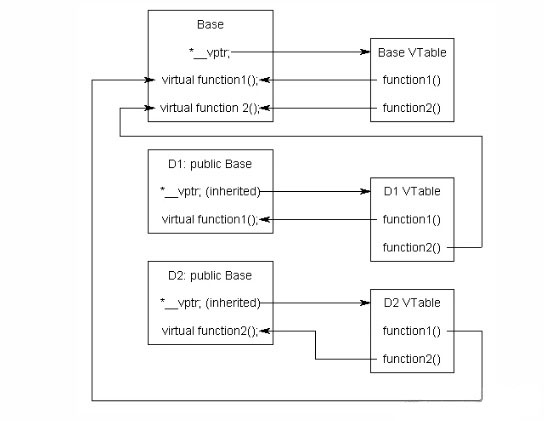
还有一个很巧妙的事情。看下面的代码:
1 | D1 d1; |
因为 dPtr 是 Base 类型指针,它只指向 d1 对象的 Base 类型部分(即,指向 d1 对象中的 Base 子对象),而 vptr 也在 Base 类型部分。所以 dPtr 可以访问 Base 类型部分中的 vptr 。同时,这里注意, dPtr->__vptr 指向的是 D1 的虚拟函数表,这是在 d1 初始化时就确定的。所以结果,尽管 dPtr 是 Base 类型指针,但它能够访问 D1 的虚函数表。
所以当调用dPtr->function1()时,发生了这些事情:
- 程序识别到
function1()是一个虚函数。 - 程序使用
dPtr->__vptr获取到了D1的虚函数表。 - 它在
D1的虚函数表中寻找可以调用的function1()版本,这里是D1::function1()。 - 所以这次调用实际调用的就是
D1::function1()。
4. 含有虚函数的类的size问题?
- 如果类里只有一个虚函数,那这个类有多大?
只要有虚函数就会创建一个虚表指针,一个指针是4字节,所以这个类就是4字节。
- 那要是有两个虚函数呢?
那也是只有一个虚表指针,还是4字节。
- 扩展:类的内存布局
在没有继承的情况下,类的内存布局会根据声明顺序依次排布,且会有对齐现象,默认对齐大小为类内最大的基础类型大小。成员函数存在代码区,不占类的内存。静态变量存在全局存储区,也不占类的内存。例如:
1 | class A{ |
此时A对象的short a本来占两个字节,为了与最大的基础类型int对齐,接下来的2字节将会跳过,然后是int b的4字节,一共是8字节。如果将func1设置成虚函数,则会在类的头部出现一个虚表指针,那么A就是12字节。
虚函数表会单独对齐,例如,将b改为double类型,类内存的布局就是:4字节虚表指针,4字节对齐,2字节short a,6字节对齐,然后是8字节的double b,一共是24字节。
- 一个空类是多大?
一个空类理论上来说是0字节,但是编译器会为其加入1字节,这是为了它的每个对象都有独一无二的地址。例如对象a的地址是0x00000000,那对象b的地址就不可能再是0x00000000,起码也是0x00000001,这就意味着对象a占据了1字节的空间。 当另一个类继承了这个空类时,这个空类的内存就变回0字节了。
5. 虚函数和纯虚函数的区别?
虚函数由基类定义一个默认的函数,子类在继承时可以重写一个自己专属版本,也可以直接采用基类的默认函数;而纯虚函数则由基类给出声明,子类必须自行完成定义。含有纯虚函数的类被称作抽象类,无法直接创建实例,需要被继承后创建子类的实例。
6. 你的项目里用到了大量的锁,有什么优化方式吗?
我的回答:我目前是获得一次锁只从队列中获取一个任务,可以设计成获得一次锁就从队列里获取若干个任务一起处理,这样可以均摊锁的成本。
7. 有没有可能完全不用锁?
我的回答:可以加一层代理,由一个线程统一对任务队列进行管理,接到任务时主动指定某个线程并将其唤醒处理,不使用锁的机制抢任务处理。
8. 你的项目实现了注册和登录功能,如何保证(传输的过程和存放)的数据安全?
我的回答:不是很了解,可以加密,传输密文,或改用HTTPS。
9. 那你知道HTTPS的原理吗?
有点长,回头再来学。
10. 你知道内存分配的方式吗?比如malloc/jemalloc之类的
我的回答:只知道malloc,但知道操作系统级别的内存分配方式,面试官让我展开说说,我就说了一些操作系统的内存管理方式,比如说连续静态分配、动态分区、分页式之类的。追问如何减少碎片
malloc(size_t size):C/C++标准库的函数,分配size字节的内存,返回所分配区域的第一个字节的指针,如果内存不够就返回NULL。不会对空间进行初始化。calloc(size_t num, size_t size):为一个大小是num的数组分配内存,每个元素的大小是size,返回指向所分配区域的第一个字节的指针。如果内存不够就返回NULL。每个元素会被初始化为0。alloca(size_t size):在栈上申请内存,不需要free函数释放。很快,适合小的分配。但是可移植性差,不推荐使用。tcmalloc:google的内存分配管理模块jemalloc:BSD的内存分配管理模块
11. HTTP报文由哪些结构组成?消息报头都有哪些字段?
请求报文:
请求行(请求方法、URL、HTTP版本)
请求头部(客户端信息、目标Host、需求语言等信息)
空行
请求数据(POST的信息)
响应报文:
状态行(HTTP版本、状态码)
消息报头(必备Content-Type和Content-Length,还有服务器信息、文件最后更新时间、压缩算法等)
空行
响应正文(HTML代码、图片数据等)
12. HTTP状态码有哪些?
信息响应,以1开头。例如
100 Continue,POST方法可能会将请求头和请求数据分成两个数据包进行发送,服务器收到请求头时就会先响应一个100 Continue表示请求头没有问题,可以继续发请求数据。成功响应,以2开头。例如
200 OK。重定向消息,以3开头。例如
301 Moved Permanently,表示请求资源的URL已被永久更改,会在响应中给出新的URL。还有307 Temporary Redirect和308 Permanent Redirect等。客户端错误响应,以4开头,例如
400 Bad Request、403 Forbidden、404 Not Found服务端错误响应,以5开头,例如
502 Bad Gateway、503 Service Unavailable等。
13. Linux环境下,程序出错,错误信息会记录在什么文件里?
我答了个errno,面试官指出这是系统调用的错误信息;我说那我不知道了,我只见过stdout的错误信息,比如段错误之类的;面试官追问,那除了段错误还有什么呢,我回忆了一下说不知道了(其实还有算术错误,比如分母为0、无对应操作符、返回值类型有误、未定义变量/函数、类型溢出等等)。
会存放在core文件里,可以使用gdb打开core文件(指令为gdb [exec file]] [core file],例如 gdb ./a.o ./core)。指定core文件进入gdb后,gdb会自动显示如下的错误信息,包括错误的类型、出错的线程、代码所在行以及具体是哪句代码。
1 | Core was generated by `./a.o'. |
也可以使用where和bt指令查看,但不会显示出具体的代码。
1 | (gdb) where |
备注:
- 使用
ulimit -c查看core文件的最大大小,如果是0则不会生成core文件。如果指定文件大小,但生成的信息超过此大小,就会被裁剪而生成不完整的core文件,在调试此文件时gdb会提示错误。一般直接设置成ulimit -c unlimited就可以了。 - 如果要查看具体出错在哪行,使用g++编译时要加上
-g获取调试信息,否则只会显示在哪个线程出错。 - core文件的生成路径记录在
/proc/sys/kernel/core_pattern这个文件里。
14. 手撕代码
给定一个正整数N,打印出比N大的最小的“非重复数”(相邻数位不同,例如1120是重复数,1210是非重复数)。
测试用例:19901, 9901, 1120, 9
思路:找到最高位的相邻数位相同的位置,对其进行处理(变得更大,必要时进位),剩下的用010101…填充即可。
问题:如果使用测试用例219901,在一次进位后会变成22开头的数字,需要第二次进位。试图以循环方式处理,被面试官称为“缝缝补补”,很不优雅。
解决方案:从右往左遍历,每扫到重复的就进行一次增加处理,直到全部相邻数位都不重复
进阶:不使用string。
1 | int main() { |
DLC.1 对象切片
对象切片:当一个函数的参数是按值传递的,且传递的对象类型是基类。当调用该函数时,传入派生类对象时,会自动向上转型,将对象转换成基类对象,并删除派生类中新增的任何成员。例如:
1 | class A { |
上面这段代码的输出是
1 | this is B |
由此可见,A a = b这句代码中发生了对象切片。因为这里创建了一个新的A类对象,自然就创建了新的A类的虚表指针,指向基类的函数。但是注意,如果传递指针,则不会发生对象切片,因为没有调用类的构造函数,只是一个指针的复制或拷贝过程,例如:
1 | class A { |
上面的代码输出是:
1 | this is B |
只有新创建的a1对象调用了基类的函数。
DLC.2 静态联编和动态联编
联编:将源代码中的函数调用解释为执行特定的函数代码块的过程称为函数名联编。意思就是,同一个名称的函数有多种,联编就是把调用和具体的实现进行链接映射的操作。
联编中,C++编译器在编译过程中完成的编译叫做静态联编。
但是重载、重写、虚函数使得静态联编变得困难。因为编译器不知道用户将选择哪种类型的对象,执行具体哪一块代码。所以,编译器必须生成能够在程序运行时选择正确的虚函数的代码,这个过程被称为动态联编。
编译器对非虚方法使用静态联编,对虚方法使用动态联编。
例如:
1 | class A { |
上述代码运行的结果是:
1 | this is A |
可以看到,编译器对虚函数进行了动态联编,分别调用了基类和子类的函数;而对非虚函数进行了静态联编,总是调用基类的函数。
DLC.3 公有、保护、私有继承
继承时,我们要选择继承方式,例如:class B : public A就是B以公有继承的方式继承了A。
而这个public修饰的是从类A继承来的对象在B里的新权限。例如:
1 | class A { |
如果类B对其进行公有继承:a为A类私有,无法继承;b被继承为保护对象;c被继承为公有对象。
如果类B对其进行保护继承:a为A类私有,无法继承;b被继承为保护对象;c被继承为保护对象。
如果类B对其进行私有继承:a为A类私有,无法继承;b被继承为私有对象;c被继承为私有对象。
规律:以最严格的权限为准。
DLC.4 类和结构体的区别
在C的时代,struct不能包含函数。
但是在C++时代,struct不仅可以包含函数,还可以包含虚函数、可以继承和多态、可以使用模板,甚至跟class可以互相继承,几乎和class没有区别。C++保留struct的一大原因(甚至可能是唯一原因)就是为了兼容C。
但是区别还是有的。
- struct的成员默认是public;class的成员默认是private。
- struct默认是公有继承;class默认是私有继承。默认继承方式以子类为准。
- struct不能定义模板参数,class可以(就像typename)。
还有一个细节共同点:struct和class如果定义了构造函数,就都不能用大括号初始化(A a{5};),如果没定义构造函数,且成员变量都是公有的,就可以使用大括号初始化。
reference
牛客网 C++面经