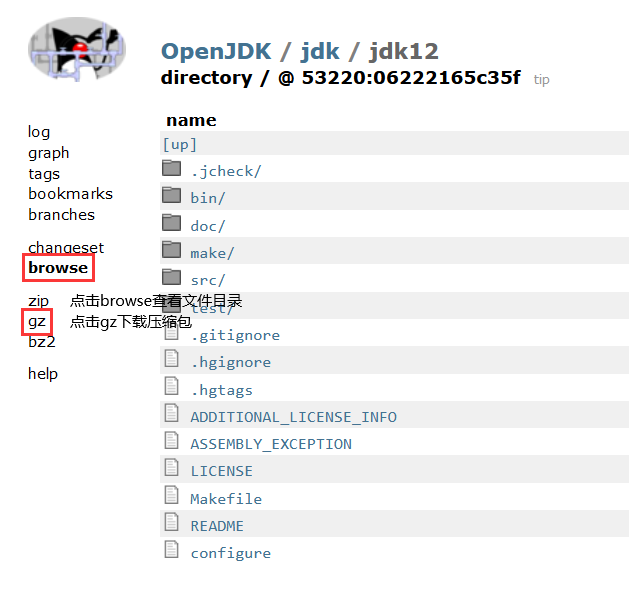
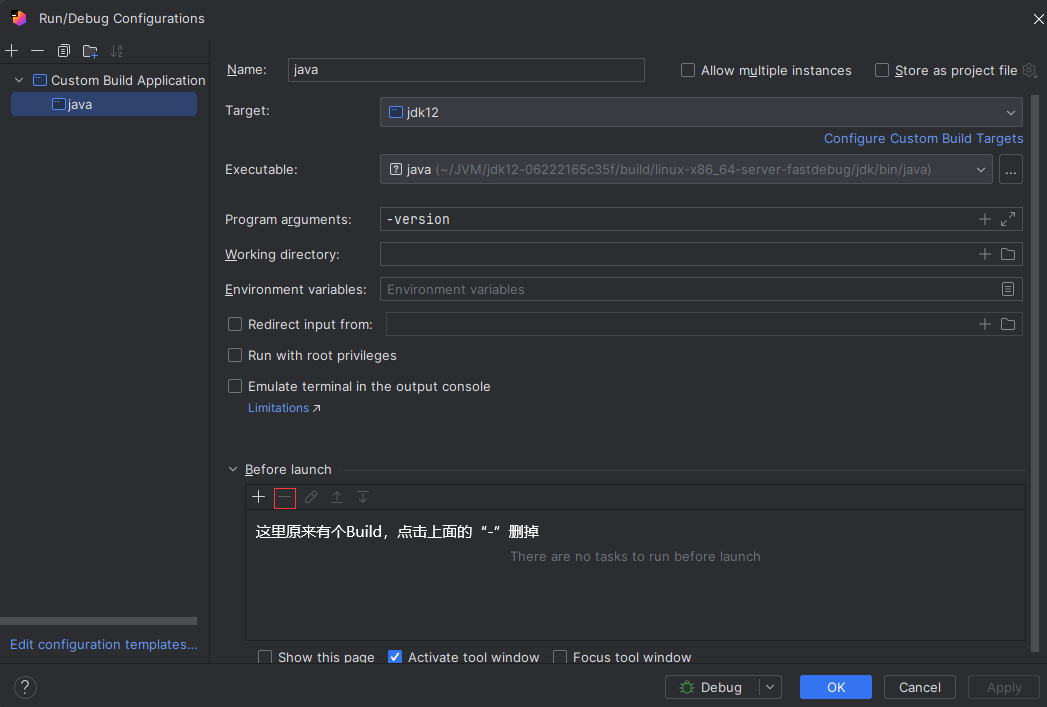
CAS:Compare And Swap,解决多线程并行情况下使用锁造成性能损耗的一种机制,CAS操作包含三个操作数——内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。无论哪种情况,它都会在CAS指令之前返回该位置的值。CAS有效地说明了“我认为位置V应该包含值A;如果包含该值,则将B放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。
=== Output from failing command(s) repeated here === * For target hotspot_variant-server_libjvm_objs_arguments.o: In file included from /usr/include/string.h:495, from /home/dzc/JVM/jdk12-06222165c35f/src/hotspot/share/utilities/globalDefinitions_gcc.hpp:35, from /home/dzc/JVM/jdk12-06222165c35f/src/hotspot/share/utilities/globalDefinitions.hpp:32, from /home/dzc/JVM/jdk12-06222165c35f/src/hotspot/share/utilities/align.hpp:28, from /home/dzc/JVM/jdk12-06222165c35f/src/hotspot/share/runtime/globals.hpp:29, from /home/dzc/JVM/jdk12-06222165c35f/src/hotspot/share/memory/allocation.hpp:28, from /home/dzc/JVM/jdk12-06222165c35f/src/hotspot/share/classfile/classLoaderData.hpp:28, from /home/dzc/JVM/jdk12-06222165c35f/src/hotspot/share/precompiled/precompiled.hpp:34: In function ‘char* strncpy(char*, const char*, size_t)’, inlined from ‘static jint Arguments::parse_each_vm_init_arg(const JavaVMInitArgs*, bool*, JVMFlag::Flags)’ at /home/dzc/JVM/jdk12-06222165c35f/src/hotspot/share/runtime/arguments.cpp:2472:29: /usr/include/x86_64-linux-gnu/bits/string_fortified.h:106:34: error: ‘char* __builtin_strncpy(char*, const char*, long unsigned int)’ output truncated before terminating nul copying as many bytes from a string as its length [-Werror=stringop-truncation] 106 | return __builtin___strncpy_chk (__dest, __src, __len, __bos (__dest)); ... (rest of output omitted)
* All command lines available in /home/dzc/JVM/jdk12-06222165c35f/build/linux-x86_64-server-fastdebug/make-support/failure-logs. === End of repeated output ===
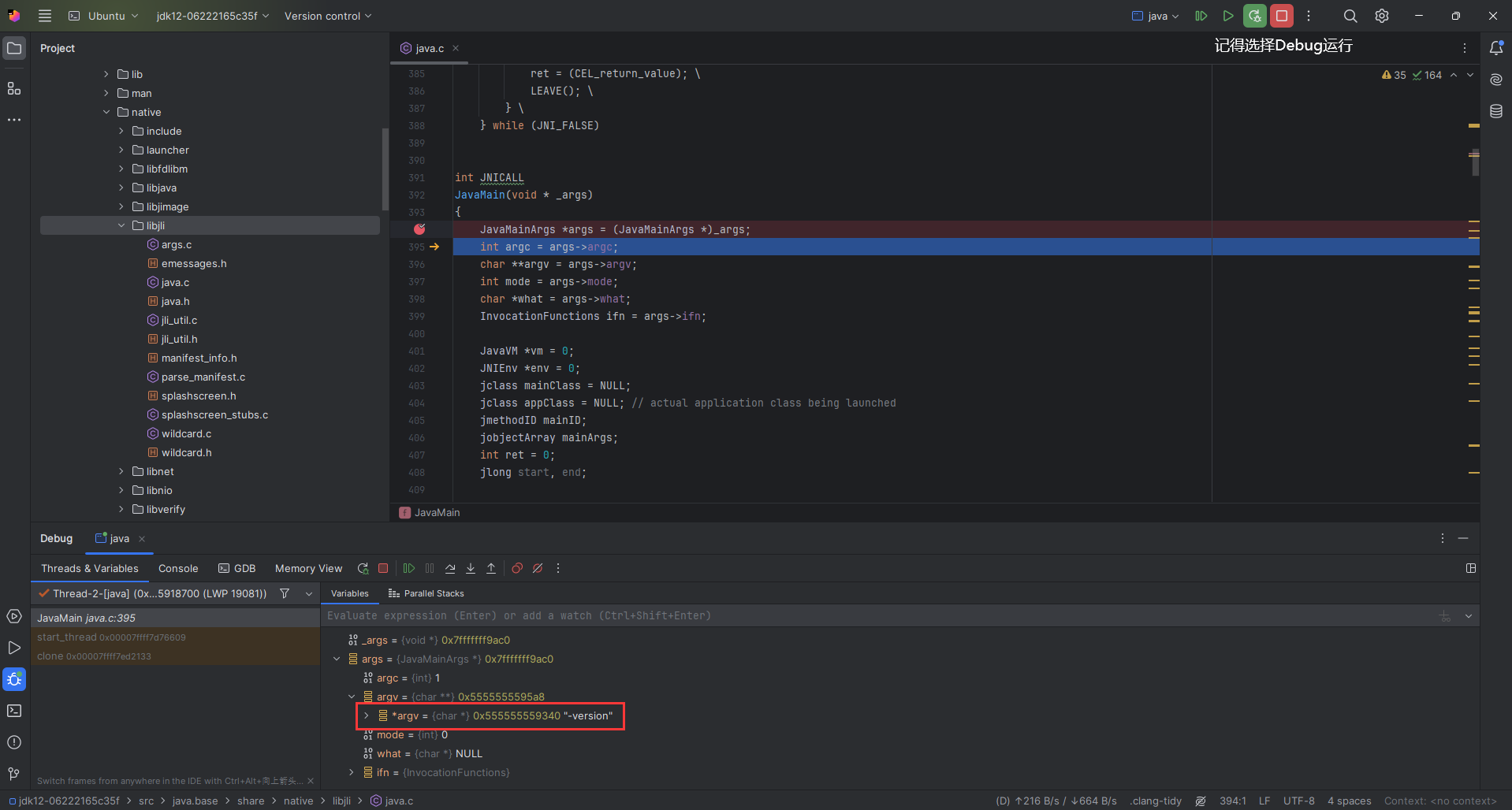
Core was generated by `./a.o'. Program terminated with signal SIGFPE, Arithmetic exception. #0 0x000055f9f4f5db7b in main () at ./a.cpp:24 24 cout << 1/a << endl;
也可以使用where和bt指令查看,但不会显示出具体的代码。
1 2 3 4
(gdb) where #0 0x000055f9f4f5db7b in main () at ./a.cpp:24 (gdb) bt #0 0x000055f9f4f5db7b in main () at ./a.cpp:24
r.GET("/welcome", func(c *gin.Context) { first := c.Query("first") last := c.Query("last") out := "hello, " + first + last c.String(http.StatusOK, out) })
HTML()用于返回一个HTML页面,第一个参数是返回的HYTTP状态码,第二个参数是要返回的页面的路径,第三个参数是需要嵌入到HTML中的数据(如果HTML中出现{{.msg}},即Gin的模板语法,则会用"this is a message from server."代替)。在使用这个函数之前,需要用LoadHTMLGlob()或LoadHTMLFiles()将HTML页面文件从硬盘加载进内存中,其中前者可以一次加载整个目录下的所有文件,而后者则单独加载某一个文件。例如:
1 2 3 4 5 6
r.LoadHTMLFiles("root/index.html") // 或 r.LoadHTMLGlob("root/*") r.GET("/reg", func(c *gin.Context) { c.HTML(http.StatusOK, "index.html", gin.H{ "msg": "this is a message from server.", }) })
classSolution { public: boolsplitArraySameAverage(vector<int>& nums){ int n = nums.size(); int sum = accumulate(nums.begin(), nums.end(), 0); int m = n / 2; unordered_map<int, unordered_set<int>> map;/* cnt,sum */ for (int i = 0; i < (1 << m); i++) { int temp = i; int tsum = 0, tcnt = 0; int idx = 0; while (temp > 0) { if (temp & 1) { tsum += nums[idx]; tcnt++; } idx++; temp >>= 1; } map[tsum].insert(tcnt); } int r = n - m; for (int i = 0; i < (1 << r); i++) { int temp = i; int tsum = 0, tcnt = 0; int idx = 0; while (temp > 0) { if (temp & 1) { tsum += nums[m + idx]; tcnt++; } idx++; temp >>= 1; } for (int j = max(1,tcnt); j < n; j++) { if (j * sum % n != 0) continue; int t = j * sum / n; if (map[t - tsum].count(j - tcnt)) returntrue; } } returnfalse; } };
RAII机制:资源获取就是初始化(Resource Acquisition Is Initialization),这是一种管理资源的方式,C++保证任何情况下,已构造的对象最终都会销毁,即它的析构函数一定会被调用。所以只要把资源的获取和释放分别封装进一个类的构造函数和析构函数,就可以保证资源不会发生“泄露”。
classconnection_pool { private: connection_pool(); ~connection_pool(); string user; string passwd; string DatabaseName; bool close_log; /* If true, the connection pool won't write logs. */ int max_conn; locker m_locker; list<MYSQL*> connList; sem m_sem; /* sem > 0 means there is free connections. */ public: static connection_pool* get_instance() { static connection_pool instance; return &instance; }
voidinit(string user, string password, string name, int maxconn, bool close_log = true); MYSQL* getConnection(); /* Get a free connection from pool. */ boolreleaseConnection(MYSQL *conn); /* Return a connection into the pool. */ voiddestroyPool(); };